


Modern Lakehouse Architecture: Key Solution Components for Scalable Analytics ❅

Information has become one of the most important resources a company can have. This includes information on their customer, processes, products, competitors and anything related to the fields in which they operate. As the years progressed, the rate at which data was generated accelerated, giving rise to the term ‘big data’.
In my earlier post, I covered the Data life cycle stages: Ingestion, storage, processing, analysing the data & visualisation.
The COAA model, which stands for Collect, Organise, Analyze, and Act, offers a straightforward and intuitive way to visualise the data landscape and comprehend the progression of data from collection to insight. This framework serves as a fundamental approach to data management and analytics and remains widely utilised today. This can be represented as a 4-layer model to capture all the necessary functionalities. Concluding it here with a generic architecture for the Data Management Platform:
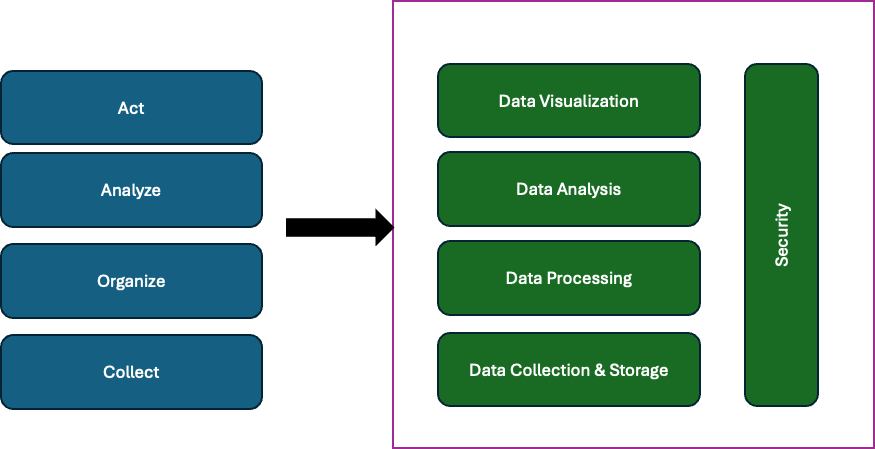
Eventually, there are multiple solutions for various industries, such as Healthcare, life sciences, Transportation, Industrial, Banking, and financial industries. The strength of all these platforms was the ability to handle the ingestion process of various data from numerous sources. There are ETL and ELT, which I have covered here. The blog covers all the aspects of Traditional and modern approaches to designing an EDW to Lakehouse architecture.
Who should read this?
This blog is intended for professionals involved in the creation of a Lakehouse, including Cloud Solution Leaders, Senior Solution Consultants, Data Architects, and AI/ML/Data Engineers. The blog provides
Prescriptive solution for each of the Lakehouse component breakups and rationale for the components section
Architectural considerations to support enterprise-class workloads
Components around the Lakehouse platform
Lakehouse Solution components
Here is a simple view of Lakehouse architecture, classified into the storage and compute layers. The Workloads layer varies from Business Intelligence, Interactive Analysis, Machine Learning, and AI models. For example, in manufacturing, data collected along the value chain can be used to optimise product lifecycles, taking all stages from product development until retirement into account. To keep up with the advances in the field and to benefit from them, enterprises need to
collect related data
store and organise the resulting huge amount of data in a structured manner
exploit the data by applying a data-driven analysis technique
Lakehouse claim to combine the desirable characteristics of data warehouses and data lakes, allowing them to serve all kinds of analytical results from a single platform.

Cloud & on-premise Service
Lakehouse need to be deployable or burstable anywhere and even span clouds in a hybrid fashion. Applications and end users must be able to access Lakehouse engines seamlessly from any location.
Burstable architecture
Burstable architecture refers to a system design where resources, such as CPU or network bandwidth, are allocated based on a baseline level of performance with the ability to "burst" to higher levels when needed. This is particularly useful for workloads that experience occasional spikes in usage but do not require high performance continuously.
Relevance to Lakehouse Architecture
Lakehouse architecture combines the best features of data lakes + warehouses, providing a unified platform for storage, processing, and analytics. Burstable architecture is relevant in terms of resource optimisation(Data processing & Cost management), Scalability & Flexibility. This approach aligns well with the goals of modern data platforms, providing a robust foundation for advanced analytics and data management.
Data Storage
In a Lakehouse, the support for Structured, Semi-Structured and unstructured data and some use cases which require high performance, there is a rise of Open Data Formats. Technologies like Delta Lake, Apache Iceberg, and Hudi standardise large-scale data handling, simplifying operations for organizations. A flexible data storage architecture became essential to support diverse data types and growing volumes.
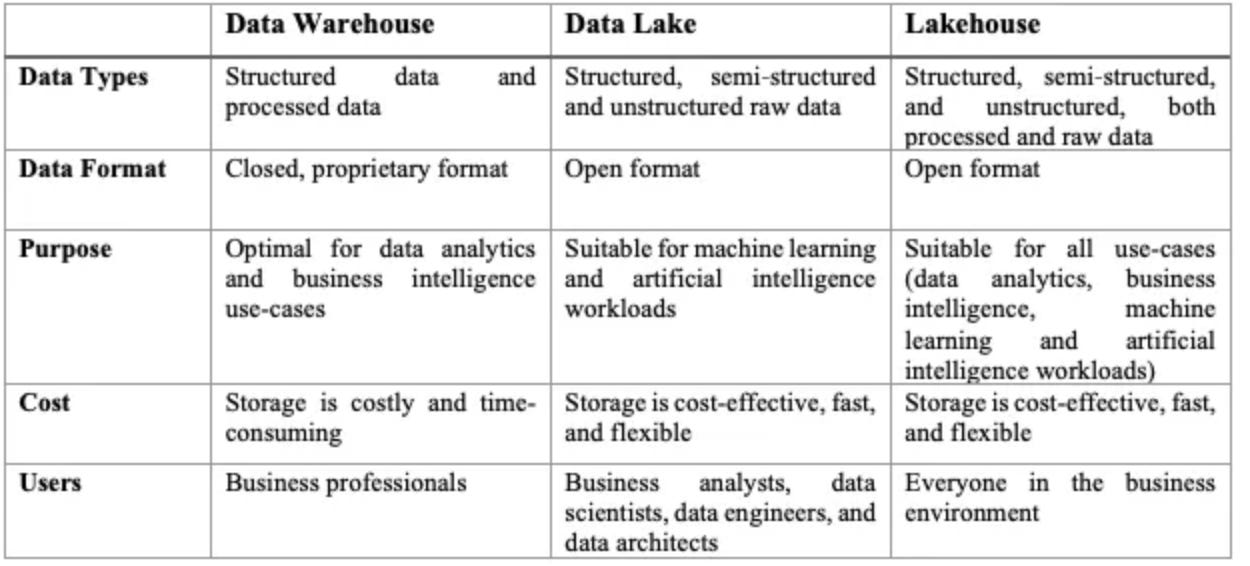
While the big data wave emerged over the years, data storage solutions also started to develop and adjust themselves accordingly. Data warehouses are seen as a traditional data storage solution. Here is a comparison between Data Warehouse, Data Lake and Lakehouse on how the three storage solutions differ accordingly to several aspects:
Open File Format
The Apache Parquet data file format is widely considered a de facto standard for storing big data. It was first introduced in 2013 as a joint project between Twitter and Cloudera, offering a state-of-the-art columnar storage format for Hadoop, designed for efficient data storage and fast retrieval.
Parquet is a widely-used file format among data engineers. It offers flexibility, scalability, and is open-source. It allows data engineers to construct petabyte-scale streaming or batch data pipelines that are both reliable and manageable. Parquet is ideal for write-once, read-many scenarios, making it well-suited for analytical workloads. It is broadly accessible and supports multiple coding languages, including Java, C++, and Python. This makes it usable in nearly any big data setting. As it’s open source, it avoids vendor lock-in.
Apache ORC (Optimized Row Columnar) is an open-source columnar data storage format that’s similar in concept to Parquet. ORC was introduced in 2013, through a partnership with Hortonworks and Facebook. It was released a month before Parquet was announced. The format was created as part of an initiative to massively speed up Apache Hive (a SQL (Structured Query Language) engine for Hadoop) and improve the storage efficiency of data stored in Hadoop.
Apache Avro is an open-source project, developed within the Apache Hadoop project, that provides (at least was designed to provide) data serialisation and data exchange services for Hadoop (however, Avro can be used independently of Hadoop, like as a data file storage format with watsonx.data). Avro was first introduced in 2009. A key feature of Avro is robust support for data schemas that change over time, referred to as schema evolution. Avro handles schema changes like missing fields, added fields and changed fields; as a result, old programs can read new data and new programs can read old data.
Open Table Format
In Lakehouse architecture, open table formats bridge the gap between flexible data storage of data lakes and the data management capabilities of data warehouses. Open table formats bring database-like features, such as ACID transactions, schema evolution, and time travel, to object storage, enabling efficient and reliable data management. Below are some popular Open Table formats:
Apache Iceberg is a high-performance, open table format that operates one level above data files. It manages table data and metadata organization, regardless of the underlying data file format (Parquet, ORC, or Avro). Iceberg offers several advantages, including ACID transaction support and time-travel capabilities, enabling users to review historical changes and quickly restore tables to previous states.
Apache Hudi is an open-source data lakehouse platform that streamlines incremental data processing and pipeline development. Optimized for data lakes and transactional workloads, it efficiently handles updates, deletes, and rollbacks. This makes it ideal for Change Data Capture (CDC) and real-time streaming applications. Hudi maintains data consistency while minimizing operational overhead.
Databricks' proprietary Delta Lake storage format, though released as open source, remains effectively controlled by Databricks as the sole project contributor—resulting in potential vendor lock-in. As the foundation for the Databricks Lakehouse Platform, it provides features such as indexing, data skipping, compression, caching, and time-travel queries.
Engines in the Lakehouse Architecture
Big data analytics applies techniques to massive datasets to uncover patterns, trends, and actionable insights. These analytics power everything from simple dashboards to complex machine learning pipelines. The quality and speed of these insights depend heavily on the query engine that processes the data.
In a lakehouse architecture, which unifies the flexibility of data lakes with the performance of data warehouses, query engines play a critical role. They are responsible for:
Data placement: Efficiently accessing and managing data across storage layers.
Query optimisation: Ensuring fast and cost-effective execution of analytical workloads.
Execution and resource management: Scaling compute resources dynamically to meet workload demands.
Presto (PrestoDB) is an open-source distributed SQL query engine for fast analytic queries against data sources of all sizes, from gigabytes to petabytes. Facebook originally developed it before making it available to the broader community.

Trino is a standalone server that provides libraries like JDBC driver and Python client for external applications. Its internal components—parser, planner, analyzer, optimizer—are not exposed as public APIs or supported libraries.
Trino is designed to perform:
Analytics - OLAP
Big Analytics
Distributed System
There are two types of Trino servers: coordinators and workers.
Apache Spark is a unified analytics engine for large-scale data processing. It offers high-level APIs in Scala, Java, and Python, and an optimized engine that supports general computation graphs for data analysis. It also includes comprehensive tools: Spark SQL for SQL and DataFrames, pandas API on Spark for pandas workloads, MLlib for machine learning, GraphX for graph processing, and Structured Streaming for stream processing.

Final thoughts
“Speed to market” & “Better Economy from your data platform” are the key trends:
Big Data and Hadoop have revolutionized the analytics space through ML models. Now, the AI wave is pushing boundaries across healthcare, manufacturing, banking, and financial industries. Lakehouse architecture streamlines the transformation of business insights into actionable strategies.
Commercial Lakehouse engines, also known as Lakehouse compute engines, are specifically designed to optimise query performance on Lakehouse architectures. They are built to leverage open data formats like Delta Lake, Apache Iceberg, and Apache Hudi, providing efficient storage and compute capabilities. Databricks, Snowflake, Dremio, and IBM’s watsonx.data are the commercial vendors available in the market. As the AI wave continues to transform industries, it's crucial to stay ahead of the curve. Embrace the power of lakehouse architectures and commercial engines to drive innovation and gain a competitive edge.
Reference:
essay.utwente.nl - Evolution of data storage
ieeexplore.ieee.org - A Lakehouse Architecture for the Management and Analysis of Heterogeneous Data
www.researchgate.net - Unified data Architecture
SpringerLinkThe Lakehouse: State of the Art on Concepts and Technologies
www.theseus.fi Lakehouse architecture in public cloud
GitHubGitHub - prestodb/presto: The official home of the Presto di…
Assessing the Lakerhouse www.scitepress.org
ApacheSparkApache Spark™ - Unified Engine for large-scale data analytic…